
Table of Contents
One of the biggest strengths of Snowflake is its flexible, usage-based pricing model. But that same pay-for-what-you-use approach means costs can quickly surprise you, especially
when running complex or exploratory queries. Predicting the cost of a Snowflake query before you run it is essential for budgeting, controlling spend, and maintaining trust with stakeholders who rely on timely, cost-effective insights.
In this guide, we’ll show you practical ways to estimate what a query might cost using
Snowflake’s built-in tools, warehouse sizing considerations, and historical trends, so you can
make informed decisions before hitting execute.
Why Predicting Query Costs Matters
Snowflake bills primarily on compute time (via credits) and secondarily on storage and data
transfer. While storage and egress costs are relatively easy to plan, compute costs can
fluctuate dramatically with query complexity. Running unoptimized queries or experimenting with large data scans without awareness of potential costs can lead to:
● Unexpected spikes in your Snowflake bill
● Bottlenecks that slow down other workloads
● Pressure on your warehouses, increasing queue times for critical jobs
Already working on improving your Snowflake queries? See our guide on query optimization for strategies like caching and clustering that keep costs low.
Use the EXPLAIN Command for Cost Visibility
The simplest place to start is Snowflake’s EXPLAIN command. It provides the execution plan of your SQL statement without actually running it. While it doesn’t show an exact credit estimate, it gives you valuable insight into:
● Estimated bytes scanned
● Operations like joins or aggregations
● Whether pruning (thanks to clustering) will limit data reads
If you see that your query will scan a huge number of partitions or large volumes of data,
consider filtering or optimizing before executing.
Tip: Use this along with your understanding of warehouse credit rates (for example, Small =
2 credits/hour) to approximate costs based on expected execution time.
Profile Your Query with QUERY_PROFILE
Snowflake’s QUERY_PROFILE view offers more granular insights for fine-tuning, especially
for recurring workloads. While this requires the query to have run at least once, you can use it on similar past queries to predict future costs. Look for:
Execution time by step: See where most of the compute time is spent.
Bytes scanned: Helps anticipate cost if data volumes increase.
Partition pruning efficiency: Tells if clustering is reducing scan size.
Leverage Historical Usage for Future Estimates
Snowflake’s QUERY_HISTORY and WAREHOUSE_METERING_HISTORY are powerful tools to estimate costs for similar upcoming workloads.
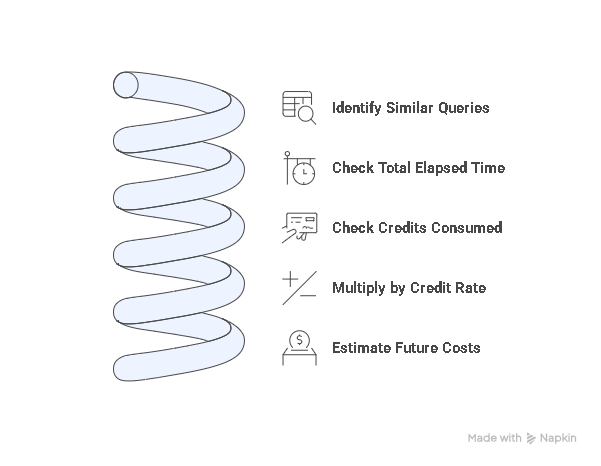
How to do it:
● Identify previous runs of similar queries.
● Check the total_elapsed_time and credits consumed in WAREHOUSE_METERING_HISTORY.
● Multiply by your credit rate.
This approach is especially helpful for scheduled ETL jobs or dashboards that regularly pull
comparable data.
Want a deeper dive into which metrics matter for performance and spend? See our post on essential Snowflake monitoring metrics.
Don’t Forget Warehouse Sizing & Concurrency Impacts
Even the most efficient query will cost more if it’s run on an oversized warehouse.
Conversely, under-sizing may slow down execution, ironically keeping the warehouse
running longer.
Key checks:
● Is your workload heavy enough to need a Large or X-Large warehouse?
● Can it run on a Small with slightly longer duration at half the credit rate?
● Are multiple queries sharing the same warehouse concurrently, improving utilization?
For a full guide on matching warehouse size to workload, explore our Snowflake query
optimization strategies.
Quick Example: Estimating Credits Before Running
Let’s say your warehouse is a Medium (4 credits/hour = ~$8/hour).
● From past queries, you see similar workloads run in 12 minutes.
● So: arduino
CopyEdit
(12 min / 60 min) * 4 credits = 0.8 credits
= ~$1.60
If you use EXPLAIN or historical profiles, this query might scan 2X the data, double your
estimate.
Predicting the cost of a Snowflake query before execution isn’t an exact science, but with the right approach, you can come surprisingly close. By using EXPLAIN plans to understand
how much data your query will scan, diving into QUERY_PROFILE to spot compute-heavy
operations, and reviewing historical query patterns to anticipate execution time, you’ll build a clearer picture of expected costs.
Combine this with thoughtful warehouse sizing to ensure you’re not paying for more power
than you need, and you’ll stay well ahead of unexpected bills. Making cost estimation a
standard part of your workflow not only protects your budget, it also builds trust across
teams who rely on fast, predictable insights.
Want Help Predicting and Controlling Your Snowflake Costs?
Frequently Asked Question (FAQ)
QUERY_PROFILE offers detailed insights into query execution time and bytes scanned, helping to predict future costs for similar queries.
Proper warehouse sizing ensures efficient query execution. Oversized warehouses lead to wasted credits, while undersized ones slow down queries and increase runtime.
While not perfect, combining EXPLAIN, QUERY_PROFILE, historical trends, and warehouse sizing allows for a reasonably accurate cost estimate before execution.