Introduction
What is Data Lake Testing
The Core Pillars of Lakehouse Quality Assurance
A comprehensive data lake testing strategy requires verifying data stability at every major stage of the ingestion and processing pipeline.
1. Data Ingestion Testing
This initial gate ensures that source data from APIs, message queues (like Kafka), or database replication logs lands in the ingestion zone intact. Tests at this stage focus on:
- File Completeness: Matching landing file byte sizes and row counts against source metadata.
- Format Validation: Ensuring semi-structured formats like JSON, Avro, or Parquet parse correctly without unhandled exceptions.
2. Data Transformation Testing
As data moves through cleansing, enrichment, and aggregation phases, transformation testing validates that your processing logic behaves exactly as expected. This involves:
- Business Rules Enforcement: Confirming calculations, lookups, and conditional logic yield correct outputs.
- Schema Drift Verification: Detecting when an upstream source alters a data type, adds an unexpected column, or drops a crucial field.
3. Data Storage and Retrieval Testing
This pillar evaluates how files are physically partitioned, cataloged, and read within the storage layer (such as AWS S3, Azure ADLS, or Google Cloud Storage). Testing ensures that partition structures match temporal or categorical design requirements, allowing analytical engines to query data efficiently.
4. Performance and Security Testing
Data lakes often hold sensitive corporate records and serve multiple downstream consumers simultaneously.
- Performance Testing: Evaluates read/write latency under high concurrent user loads.
- Security Testing: Verifies row-level and column-level access control frameworks, confirming that sensitive data is appropriately masked or restricted.
Essential Tools for Testing Data Pipelines
Data Validation Strategies Across the Medallion Architecture
Modern data platforms manage data quality using a multi-layered storage pattern known as the Medallion Architecture. Your testing strategy should adapt to the specific objectives of each layer.
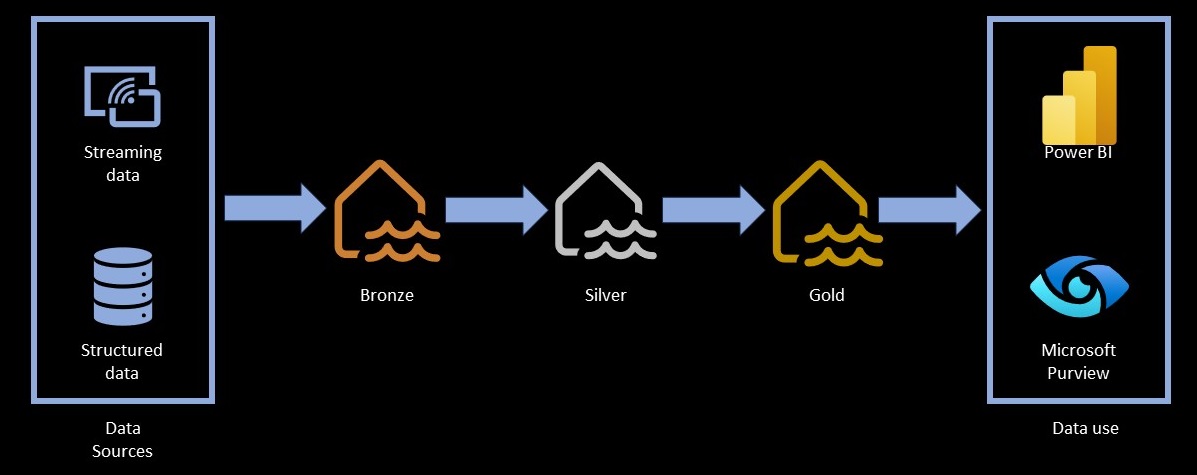
Automated Processing Validation
Automated monitoring frameworks like Great Expectations, Soda Core, or AWS Deequ are best deployed at the transition boundaries between layers. As soon as data lands in the Bronze (Raw) Zone, automated assertions run to check for basic structure, null percentages, and volume variance before promoting the files to the next layer.
Structural Verification
The Silver (Enforced) Zone transforms raw files into clean tables. Testing here relies on programmatic tools like DBeaver or SQL Workbench combined with automated test runs to verify that typecasting, schema enforcement, data deduplication, and referential integrity checks have executed perfectly.
CI/CD Pipeline Integration
To prevent buggy transformation code from breaking production environments, integrate data quality tests directly into your deployment pipelines using tools like Jenkins, GitLab CI, or GitHub Actions. Every change to an ETL/ELT script should trigger automated unit tests against a sandboxed staging data lake before being released to production.
Data Lake Testing Strategy Case study
The Complete Data Lake Testing Checklist
Common Technical Challenges & Mitigation
As data lakes expand to petabyte scale, data teams face a unique set of technical hurdles:
- Managing Massive Data Volumes: Scanning every single row across billions of records is computationally expensive and slow.
- Mitigation: Implement statistical data sampling and focus full validation checks on critical business keys, tracking trends via lightweight anomaly detection algorithms.
- Validating Real-Time Data Streams: Streaming architectures process data continuously, making traditional batch testing obsolete.
- Mitigation: Deploy continuous monitoring windows (sliding time windows) to validate data volumes and latency directly within your streaming engine before writing to disk.
- Scalability Bottlenecks: Complex data quality checks can slow down ingestion, causing upstream data queues to back up.
- Mitigation: Offload compute-heavy assertions to distributed query engines like Apache Spark or Snowflake, allowing validation steps to scale alongside your data footprint.
Best Practices for Long-Term Data Lake Health
Conclusion: Securing Trust in Your Data Architecture
Book a Free 30-Minute Meeting
Discover how our services can support your goals — no strings attached. Schedule your free 30-minute consultation today and let's explore the possibilities.
Book a Free Call