
Data Engineering Services
Data Prism provides end-to-end data engineering services, including data pipelines, integration, warehousing, automation, and scalable cloud architectures that help businesses turn raw data into reliable analytics and business intelligence.
Data Engineering Services we Offer
We bring clarity and control to complex data environments. From real-time ETL pipelines to modern data lakes and cloud migration, our services are tailored to drive agility, security and performance across your data stack.
Data Integration
Unify data from multiple sources and platforms into a single, consistent view. We synchronize systems, APIs and databases to ensure seamless access across your organization.
Data Pipeline Development
Automate the entire data journey — from ingestion to transformation and delivery. We build ETL/ELT pipelines optimized for scale, real-time streaming and efficient orchestration.
Data Warehousing
Create centralized repositories that support fast querying and scalable storage. Our solutions are designed for BI tools, dashboards and high-volume analytics.
Data Cloud Strategies
Leverage the power of cloud platforms like AWS, GCP and Azure with custom strategies that match your infrastructure, budget and growth goals.
Data Migration
Seamlessly migrate legacy systems, databases, or cloud platforms with zero data loss and minimal downtime. We ensure a secure and smooth transition to your new architecture.
Data Lake Implementation
Build modern data lakes to store structured, semi-structured and unstructured data in its raw form — enabling advanced analytics, ML and data discovery.
Data Management Services
Govern your data end-to-end — quality, lineage, ownership, and access. We bring structure to messy data estates so teams trust what they query.
Technologies We Use for Data Solutions
- JavaScript
- Node Js
- Python
- DynamoDB
- Firebase
- MongoDB
- MySQL
- PostgreSQL
- Redis
- SQL Server
- SQLite
- BigQuery
- Redshift
- Snowflake
- Apache Airflow
- Azure Data Factory
- Dagster
- Databricks
- Apache Kafka
- AWS Glue
- DBT
- Talend
- Looker Studio
- Power BI
- Tableau
- AWS
- Azure
- GCP
- Heroku
- Docker
- Kubernetes
- Postman
- Requests
- Rest
- soap
- Oauth
- SSL / TLS
Programming Languages
- JavaScript
- Node Js
- Python
Our Data Engineering Process
We follow a structured and agile development process to deliver high-quality, scalable data infrastructure.
Data Ingestion
We collect data from diverse structured and unstructured sources, including databases, APIs, and files, ensuring a continuous and secure flow into your systems for downstream processing.
Data Validation & Quality Checks
Before any transformation begins, we apply rigorous checks to validate data accuracy, completeness, and consistency, preventing issues that could compromise reporting or decision-making later.
Data Transformation (ETL/ELT)
Using ETL/ELT processes, we clean, enrich, and reformat raw data into a structured, analytics-ready format tailored to your specific business intelligence or machine learning use cases.
Data Storage
Transformed data is securely stored in high-performance storage solutions like data warehouses, lakes, or cloud-native repositories, designed to scale and support real-time or batch querying.
Data Orchestration & Automation
We automate recurring workflows and manage task dependencies using orchestration tools like Airflow or Prefect, ensuring timely, error-free, and fully governed data operations.
Data Access & Delivery
The final processed data is delivered through dashboards, APIs, or reporting layers, making it accessible to business users, analysts, and downstream systems in real time or scheduled intervals.
Success Stories
We’ve partnered with fast-growing startups and global enterprises to design intelligent data ecosystems that power smarter decisions and digital growth.
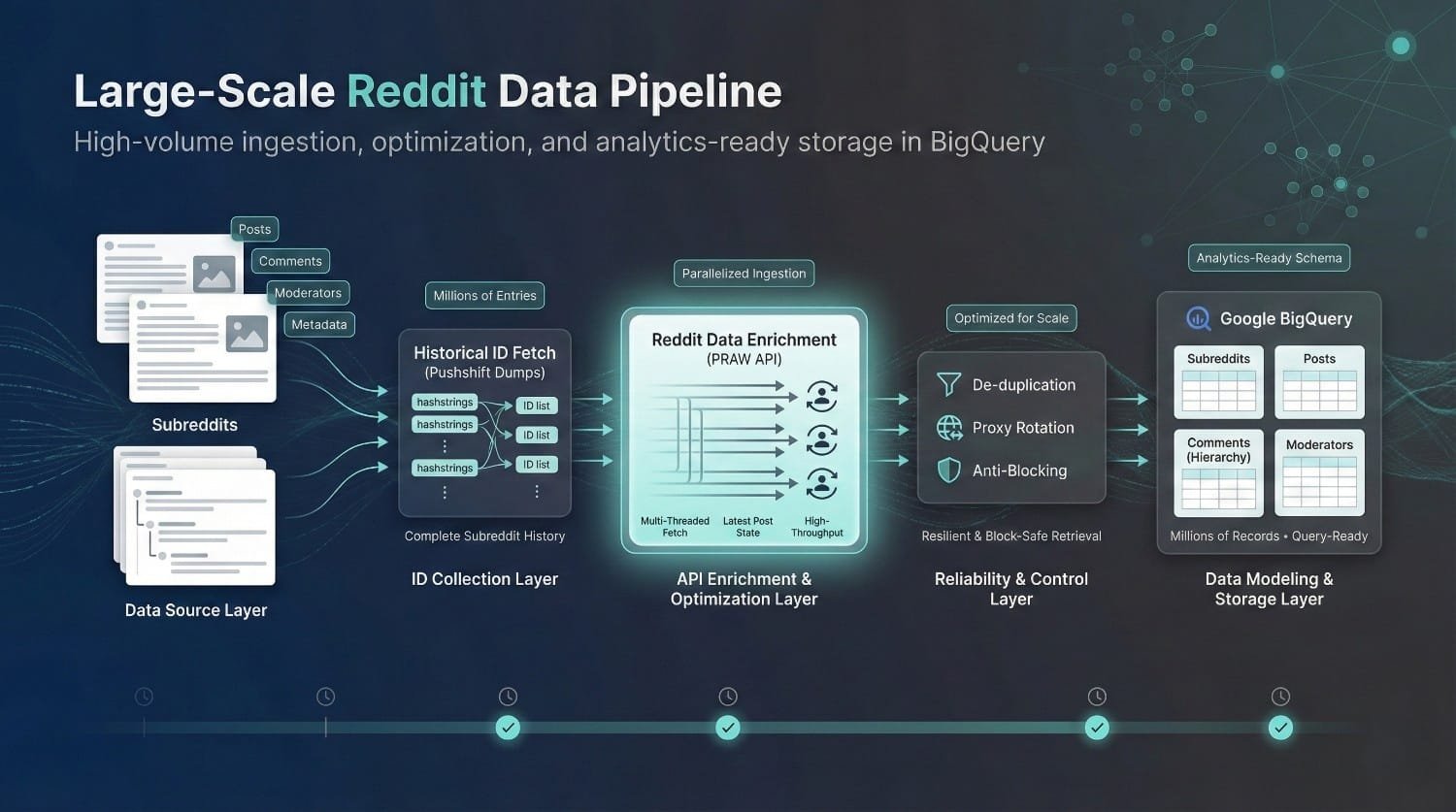
Reddit Data Collector
Boston University needed large-scale Reddit data for a research project. DataPrism built an optimized pipeline to collect, clean, de-duplicate, and store subreddit, post, and moderator data in BigQuery.
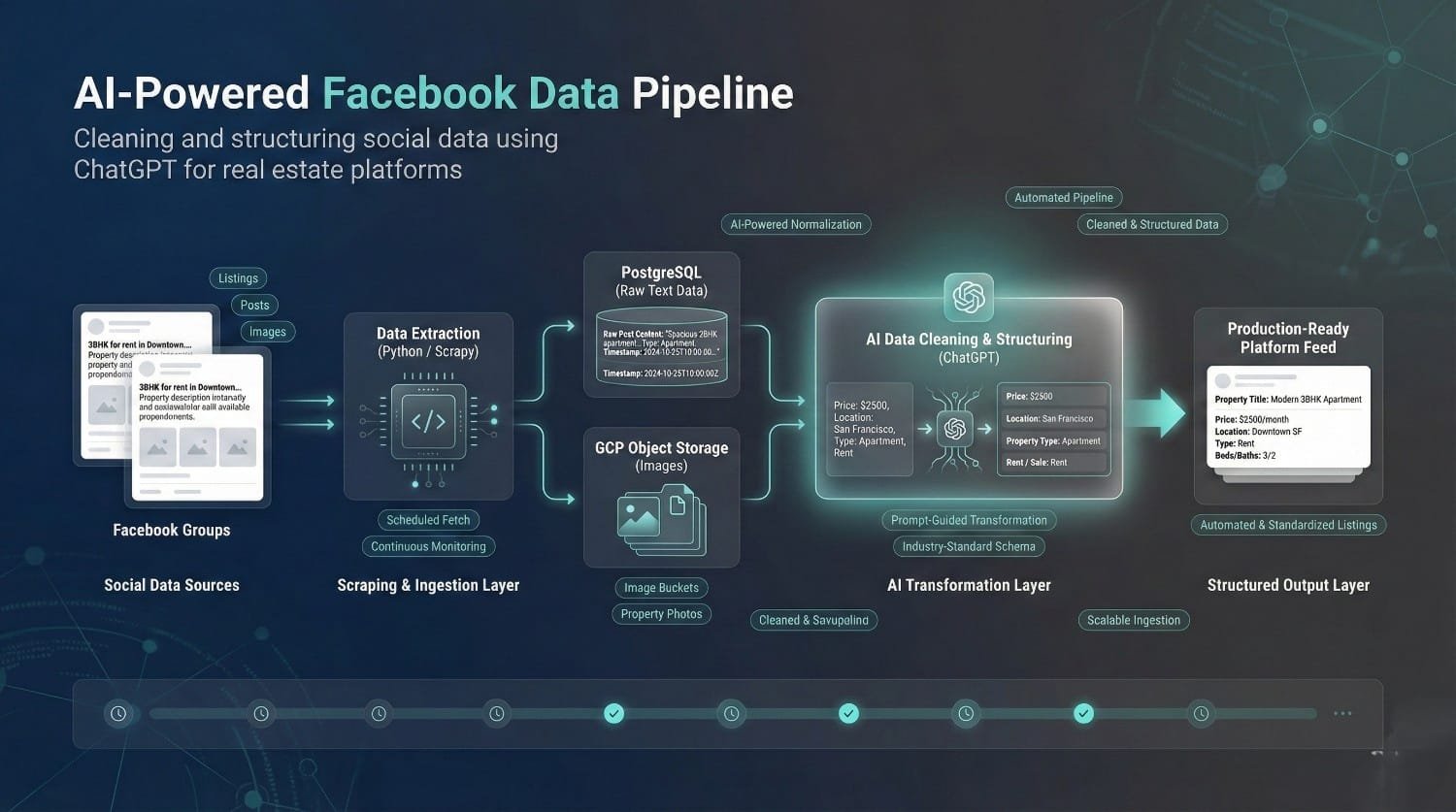
Facebook Data Pipeline using ChatGPT (for Knok’d)
Knok’d needed Facebook group data for its real estate listings platform. DataPrism built a Python and ChatGPT-powered pipeline to extract, clean, transform, and deliver the data in a structured format.
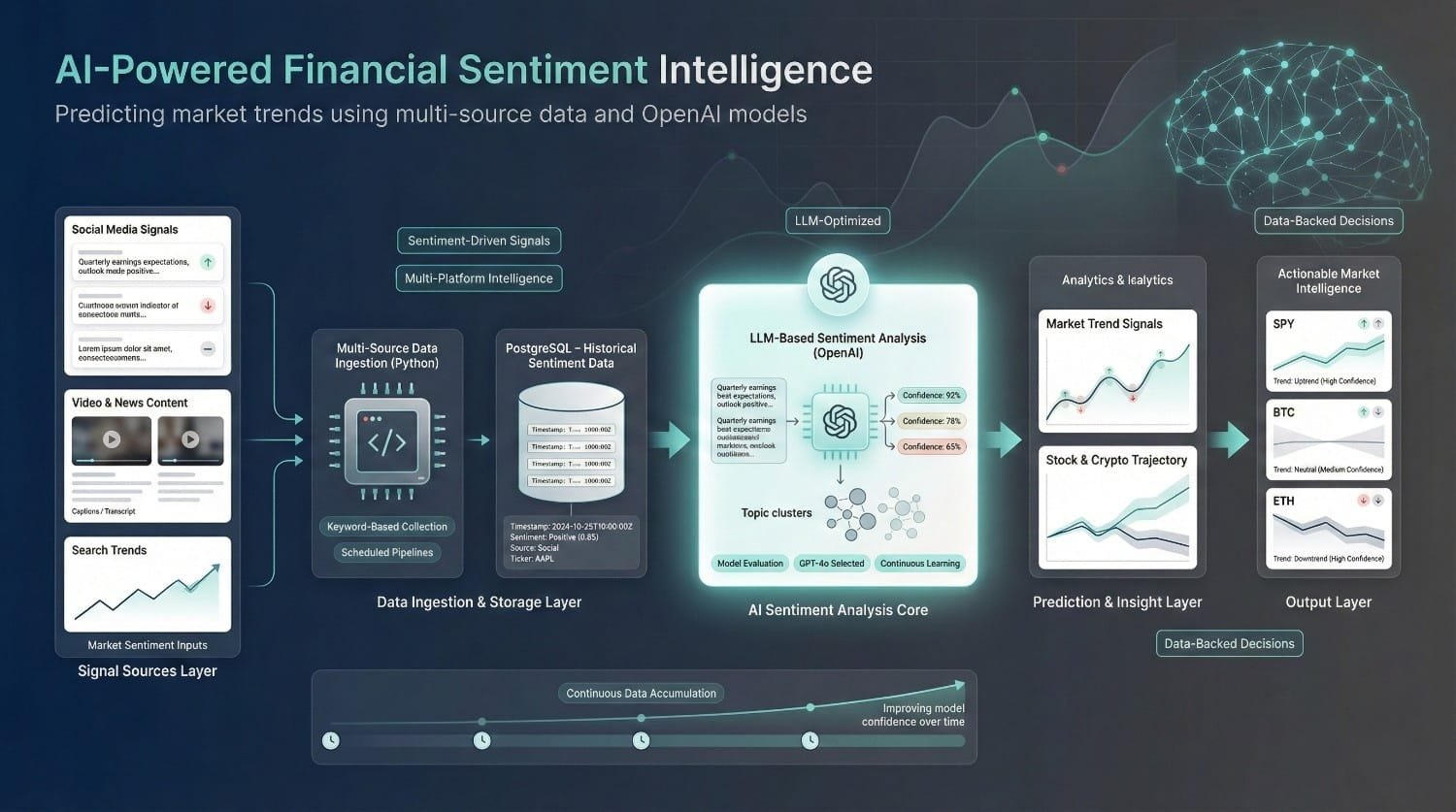
Financial Predictor using Sentiment Analysis via OpenAI API (for Maxx Source)
Maxx Source needed a sentiment analysis system for stocks and cryptocurrencies. DataPrism built a pipeline that gathered multi-platform data and used GPT-powered analysis to predict market trends.
Tell us about your project
Share your details and we'll reply within one business day.