Skip to main content
Home
Services
Data Engineering
Data Cloud Strategies
Data Integration
Data Lake Implementation
Data Management Services
Data Migration
Data Pipeline Development
Data Warehousing
Artificial Intelligence
AI App Development Services
AI Chatbot Development Services
AI Consulting & Strategy
AI Model Training & Fine-Tuning
Generative AI Solutions
Natural Language Processing (NLP)
Web Scraping
Anti-Bot Bypass & CAPTCHA Handling
E-commerce & Marketplace Scraping
Forum & Social Media Scraping
News & Publications Scraping
Real Estate & Classifieds Scraping
Structured Data Extraction
Web Crawler Development
API Integration
CRM APIs
Custom API Development
E-Commerce APIs
Marketing APIs
Real-Time Data Syncing
Social Media APIs
Third-Party API Integration
Bots and Automation
ClickUp & HubSpot Automations
Content Monitoring & Update Bots
Customer Support Bots
E-Commerce Bots
Google Sheets Integration
Lead Generation Bots Development Services
No/Low-code Automations
Slack & Discord Bots
Workflow Automation
About
Portfolio
Blog
Contact Us
Book Your Free Audit
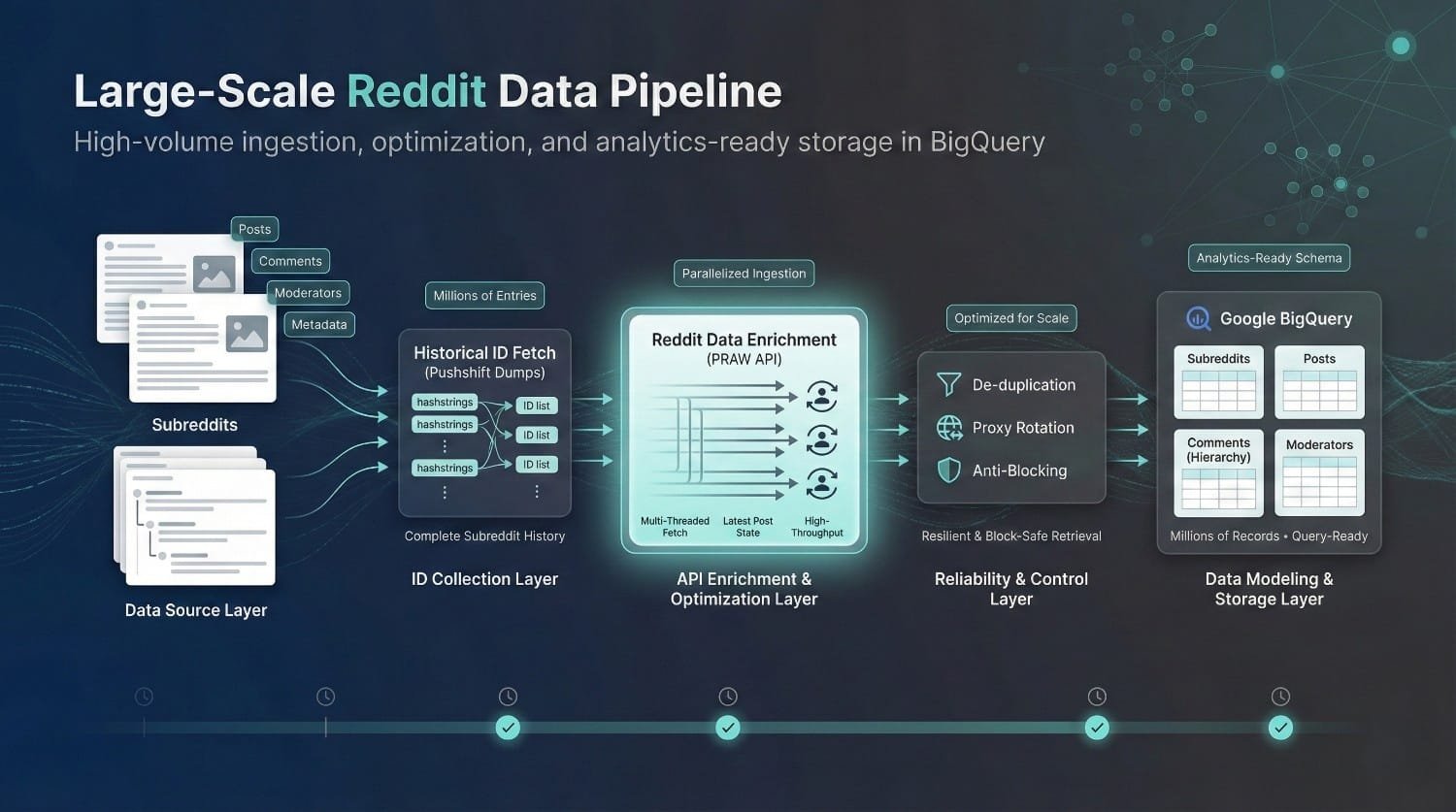
Reddit Data Collector
Web Scraping
Data Engineering
Next Project
Restoring a bak file from S3 to SQL Server in RDS
Book Consultation